
Storwize serien spænder vidt og bredt helt ned til IBM’s V3500 og helt op til deres V7000 samt FlashSystem og SAN Volume Controller (SVC).
Hele Storwize serien bygger på samme RAID kode som DS8000, men har en helt anden GUI og andre kommandoer. Selvfølgelig er den underliggende kode blevet ændret en hel del siden udgivelsen tilbage i 2010, da IBM stadig udgiver nye og hurtigere systemer med understøttelse for nyere NVMe SSD’er samt opdateringer til GUI’en og funktionaliteten.
IBM skriver selv, at systemerne har understøttelse for RAID 0, 1, 5, 6 og 10, men RAID 0 er blevet fjernet i de nyere firmware, hvilket også giver mening, da dette RAID niveau ikke tilbyder nogen form for data beskyttelse, hvilket er systemets primære funktion.
Med udgivelsen af firmware 7.6 har IBM introduceret deres egne RAID niveauer, kaldet Distributed RAID (DRAID) med niveau 5 og 6. Generelt set fungerer DRAID på samme måde som traditionel RAID, blot at pariteten er spredt ud på alle systemets diske, og når et RAID skal genopbygges efter en død disk vil det tage marginalt kortere tid, samtidig med at systemets ydelse opretholdes.
Med udgivelsen af firmware version 8 i starten af 2018 har de understøttede systemer fået en helt ny GUI der både ser og føles mere moderne, men som også følger Lenovos røde og sorte tema.
Lidt senere på året, mere specifikt i maj 2018, udkom firmware 8.1.1.3, hvilket giver mulighed for data deduplication, som er en meget nyttig funktion til at optimere udnyttelsen af pladsen, men er samtidig meget CPU afhængig. Deduplication sørger for at eliminere flere kopier af den samme data. Dette sker ved at identificere unikke bidder af data eller byte mønstre og gemmer en lille reference af denne bid eller mønster som reference, når der skrives nye data. Hvis denne bid eller dette mønster matcher en eksisterende reference, vil data ikke blive skrevet, men blot denne lille reference. Den samme bid eller det samme mønster kan forekomme rigtig mange gange, hvilket kan resultere i at mængden af data, der egentlig opbevares, er kraftigt reduceret.

Enheden vi har fået ind, er en 2078 model, specifikt 24C modellen, der indikerer, at der er plads til 24 2.5” diske, og at denne enhed er en controller.

Bagpå finder vi to controllere og to strømforsyninger, som er ret standard for hele Storwize serien, SVC ekskluderet. Hver controller har 2 RJ45 porte, 2 USB porte, 4 6Gb/s SAS porte og 4 8Gb/s fiber porte. RJ45 portene kan bruges til iSCSI, men port 1 bruges også til servicering af systemet. USB porte har samme formål, hvor kommandoer kan køres på systemet med et USB stick. Den ene SAS port bruges til at forbinde op til 19 expansion skuffer, mens de sidste 3 kan bruges af hosts, og alle 4 fiber porte kan bruges til hosts.

Inden i controlleren ser vi en stor heatsink, hvor CPU’en gemmer sig under. V5000 systemerne kører med en 4 kernet Intel Xeon E3-1265Lv2 CPU. Vi ser også en lille SATA SSD, der indeholder firmwaren, et batteri der kan skrive det sidste data og lukke systemet korrekt, hvis strømmen går, og 2 4GB RAM. V5000 kommer standard med 8GB RAM per controller, hvilket betyder at vi kan bruge nyere firmware end 7.5.0.14, da alle nyere firmware kræver 8GB RAM. Denne model er den første V5000 IBM udgav tilbage i 2013, hvilket desværre betyder, at der ikke er understøttelse for firmware version 8. Den nyeste understøttede firmware er derfor i dag 7.8.1.10.

Vi har samlet systemet igen, da det visuelt ser ud til at være i fin stand, og det er tid til at få det startet op. Når systemet er tændt og har et aktivt cluster uden fejl, vil det fremstå, som det gør på billedet herover. Dette betyder, at batterier, cluster og strømforsyninger fungerer, som de skal.
Vi kender hverken IP adresser eller kodeord til dette system, så for at få adgang skal vi først have nulstillet disse ting, og det er her USB portene skal bruges. Vi bruger et lille USB stick med en .txt fil, der hedder satask. Herigennem kan vi kører kommandoer såsom:
– satask chserviceip -default
– satask resetpassword
Alle kommandoer der er understøttet kan køres på denne måde, men det er ikke så effektivt som at få direkte adgang og køre kommandoerne igennem SSH eller igennem GUI’en.
Når USB’en bliver sat i med en kommando vil den orange LED blinke for at indikere, at kommandoen bliver kørt, og når den lyser, er kommandoen kørt, og systemet har lavet en HTML fil med navnet satask_result, og her får vi allerede afsløret en del om systemet:

Dette er kun et lille udsnit af filen, men her kan vi se, at kommandoen er kørt succesfuldt, og at der er et aktivt cluster med navnet DKIKASAN2. Service IP er nu blevet til standard 192.168.70.121 for denne controller, og når kommandoen er kørt på controller 2, vil denne få IP 192.168.70.122. Vi kan også se, at der er en fejl under ”error”, her vil der forekomme koder, vi kan slå op hos IBM for at se, hvad der er galt. I dette tilfælde er fejlen blot, at man har brugt fiber portene, men da disse ikke er sat til længere, er disse hosts selvfølgelig nede.
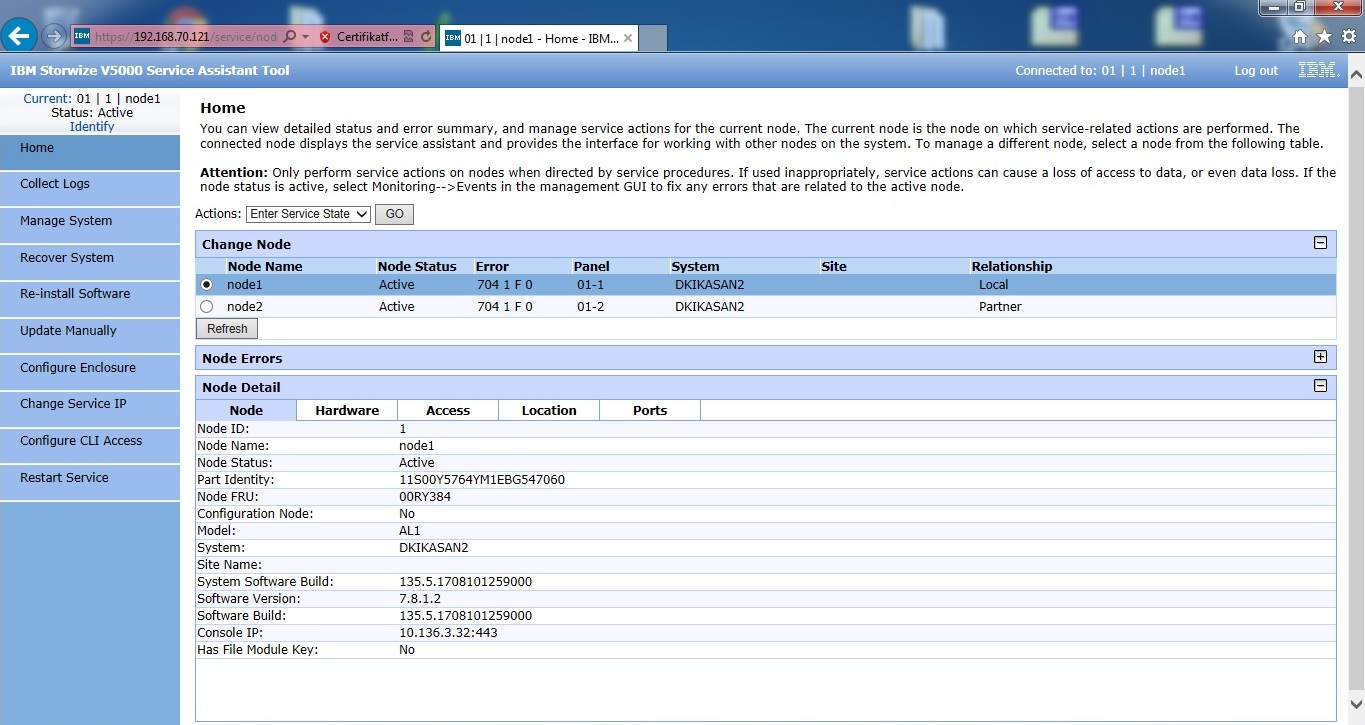
Nu hvor vi kender IP adresse, og koden til superuser kontoen er nulstillet til passw0rd, kan vi komme ind i service assistant. Det her er, vi fjerner det eksisterende cluster og laver et nyt. Jeg bruger Internet Explorer med Windows 7, da disse ældre systemer nemt kan have problemer med moderne browsere.
Jeg har været udsat for før, at vi har fået nogle systemer ind, hvor koden ikke kan nulstilles med kommandoer igennem USB. Dette er normal opførsel, da man kan slå denne metode fra. Det betyder, at hvis vi ikke kan få koden udleveret, kan vi ikke komme ind i systemet på traditionel vis.
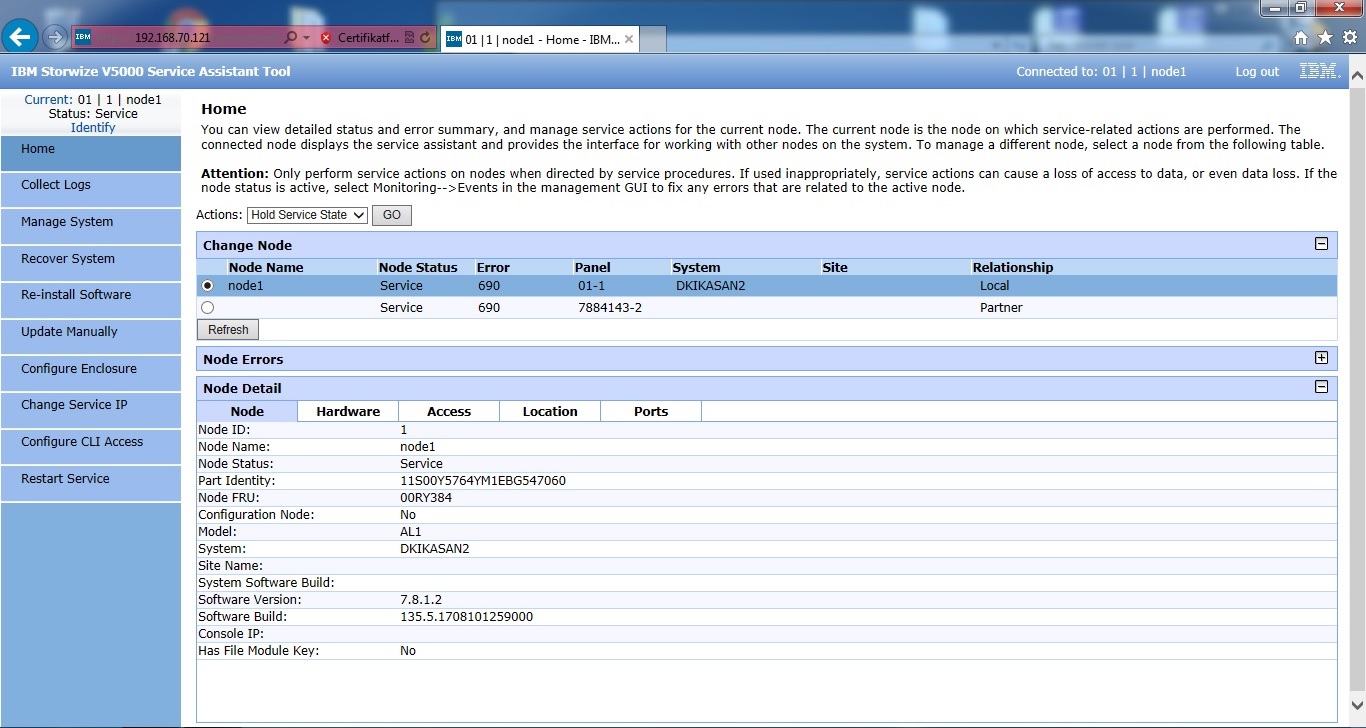
Begge controllere er sat i service, hvilket betyder at de ikke længere er aktive. Fejlkode 690 betyder blot at de bliver holdt i service tilstand, og vi kan få lov til at ændre indstillinger på dem. På billedet har jeg allerede slettet data på den ene controller, hvorfor der intet står under system, og panel navnet er ændret. Begge controllere bliver slettet, hvorefter vi kan afslutte service tilstand og begge controllere vil gå i ”Candidate” tilstand, hvilket betyder at de er klar til at forme et nyt cluster.
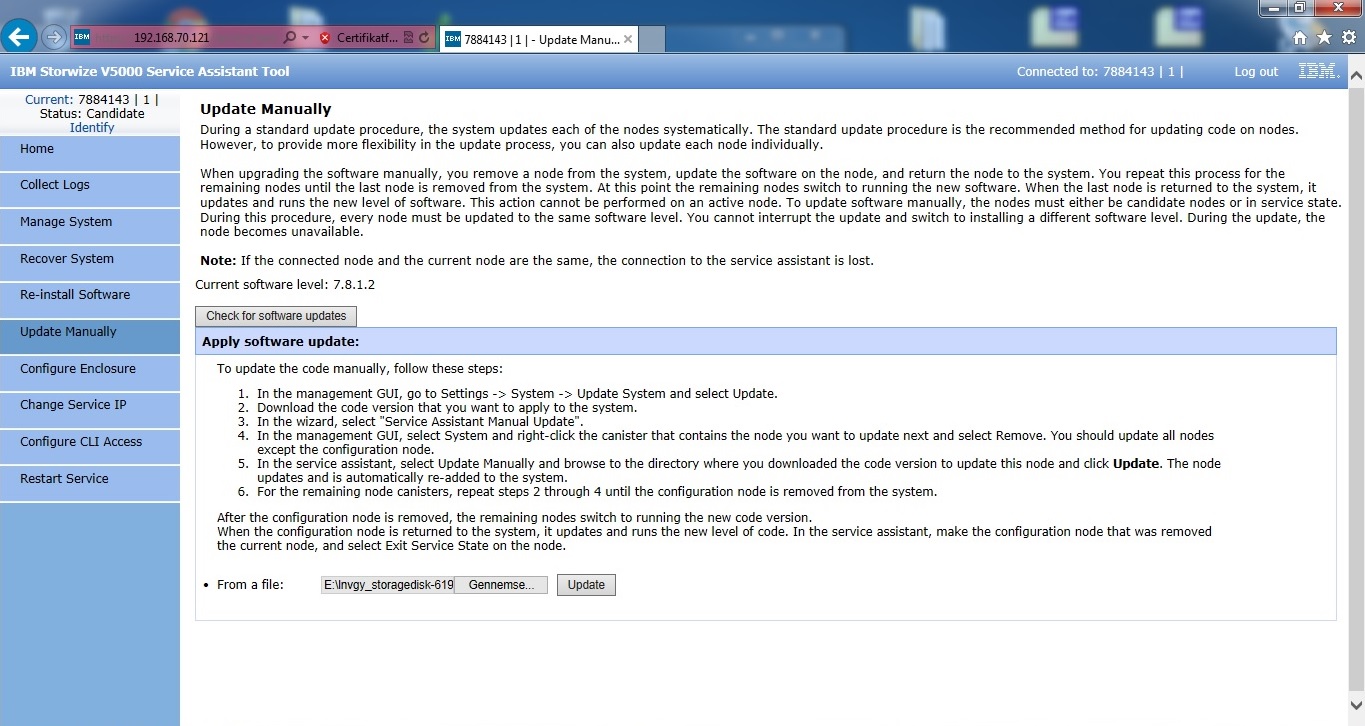
Efter at have nulstillet begge controllere er det tid til at få opdateret firmwaren til den nyeste understøttet. Firmwaren i denne enhed er version 7.8.1.2 hvilket er ret ny, men da vi som udgangspunkt altid installerer nyeste firmware, ligger vi 7.8.1.10 på begge controllere. Hvis en kunde vil have en specifik firmware, kan vi altid nedgradere denne. Firmwaren kommer i form af en fil på lidt over 500MB og uploades til begge controllere igennem service assistant.
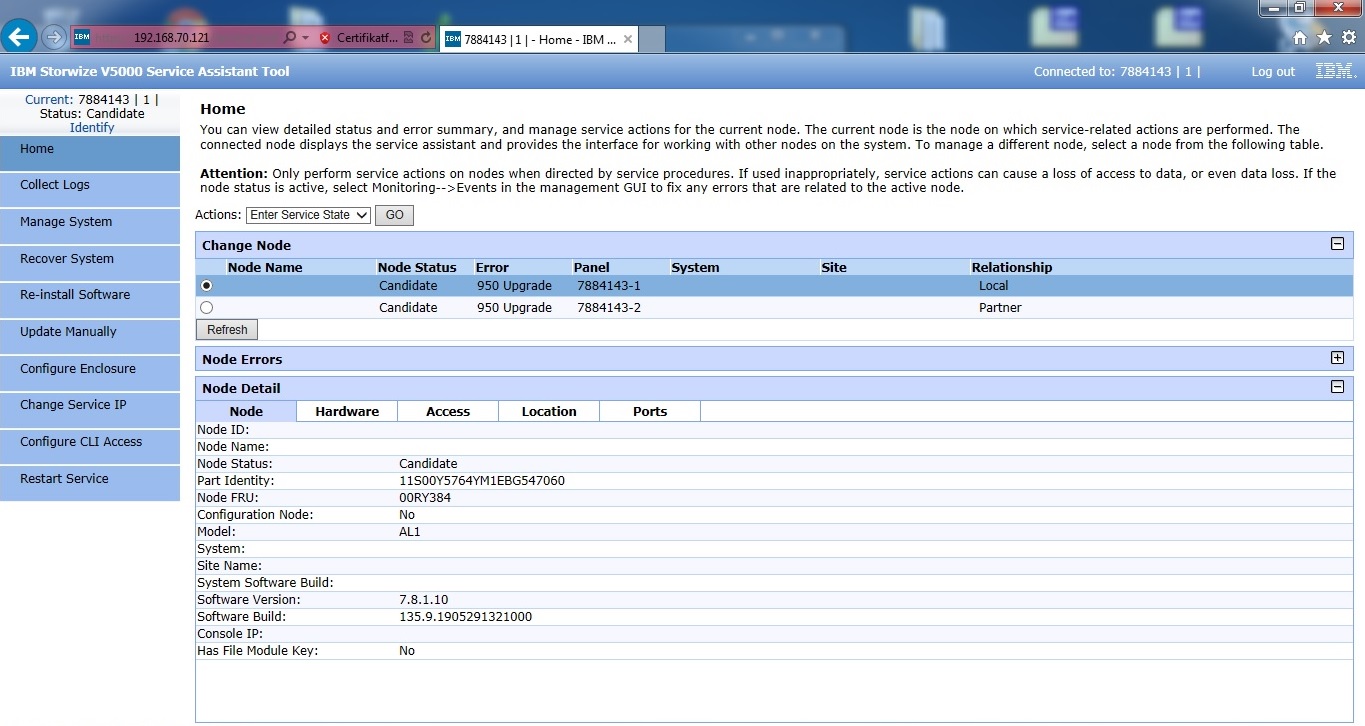
Med begge controllere opdateret til 7.8.1.10 kan vi lave et nyt cluster. Dette gør jeg blot for at få systemet til at lavet nogle småting, og sikre mig at alt kører som det skal.
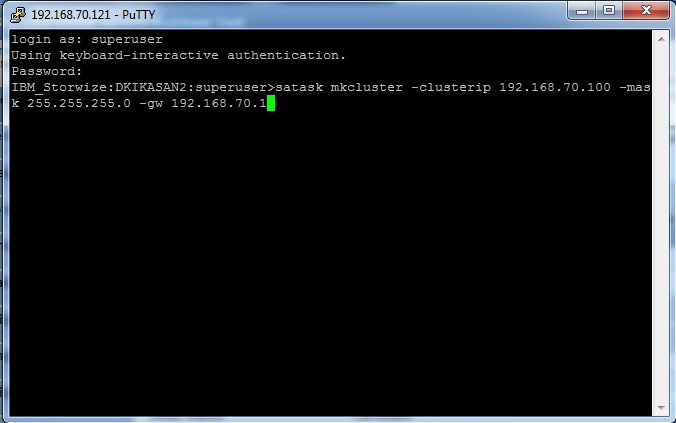
For at lave et nyt cluster bruger vi mkcluster kommandoen.
Systemet genstarter og kommer op som aktivt, og vi kan nu tilgå GUI’en igennem IP adressen 192.168.70.121, og dette billede kommer frem. Det er her den første opsætning sker, hvor man indtaster diverse informationer på systemet, men der laves ingen RAID endnu. Jeg indtaster blot tilfældige data, da vi sletter det hele igen alligevel.

Efter at have indtastet diverse data får vi dette billede, hvor alt ser ud til at se fint ud.
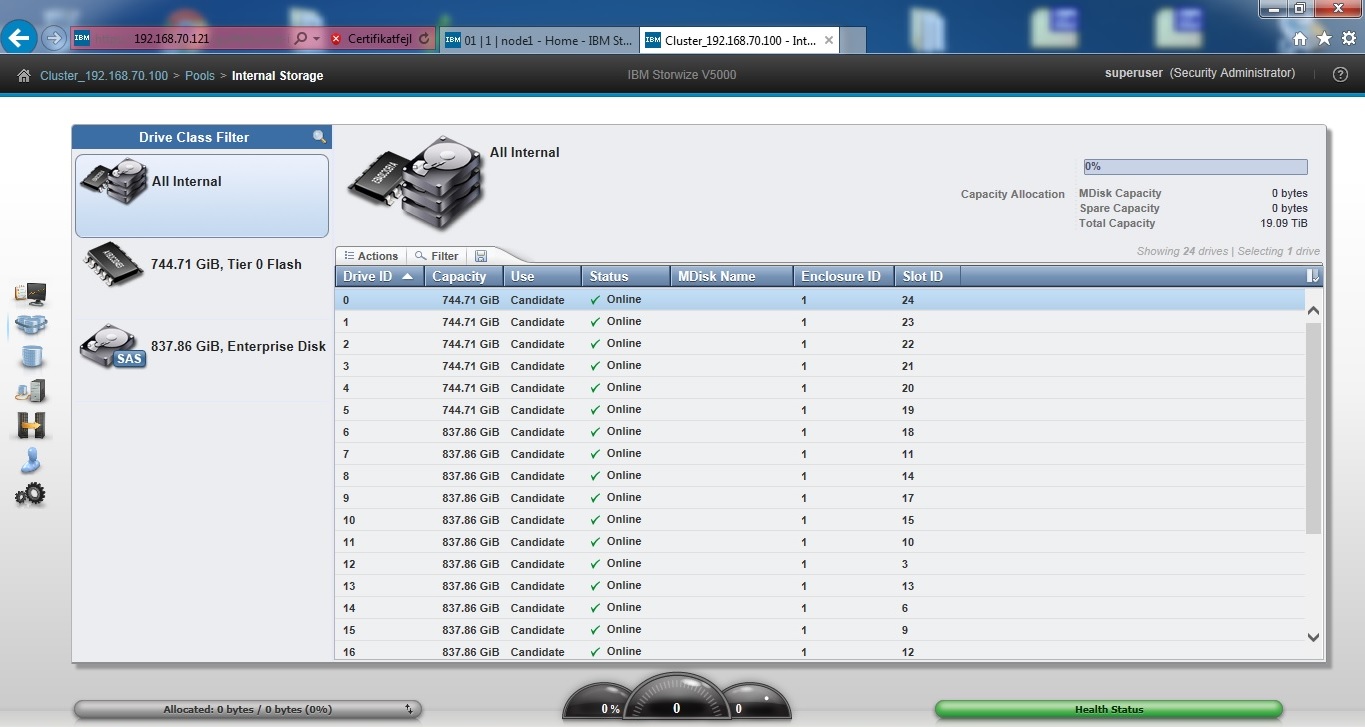
Systemet kom med 6 800GB SSD’er og 18 900GB 10K harddiske. Disse skal slettes med Certus, men inden dette vil jeg gerne lige lave et raid og lade systemet initialisere disse, blot for at få controllerne til at arbejde lidt.
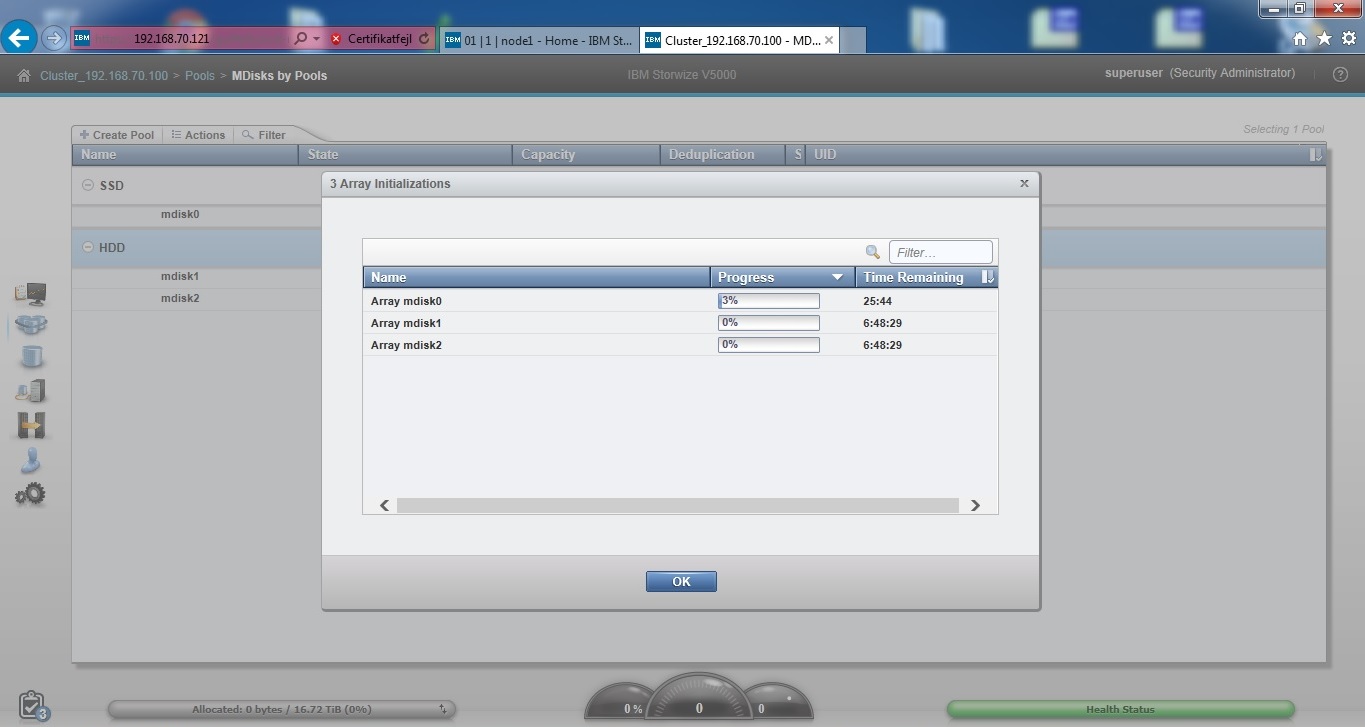
Det blev til i alt 3 RAID arrays, og systemet initialiserer disse her.
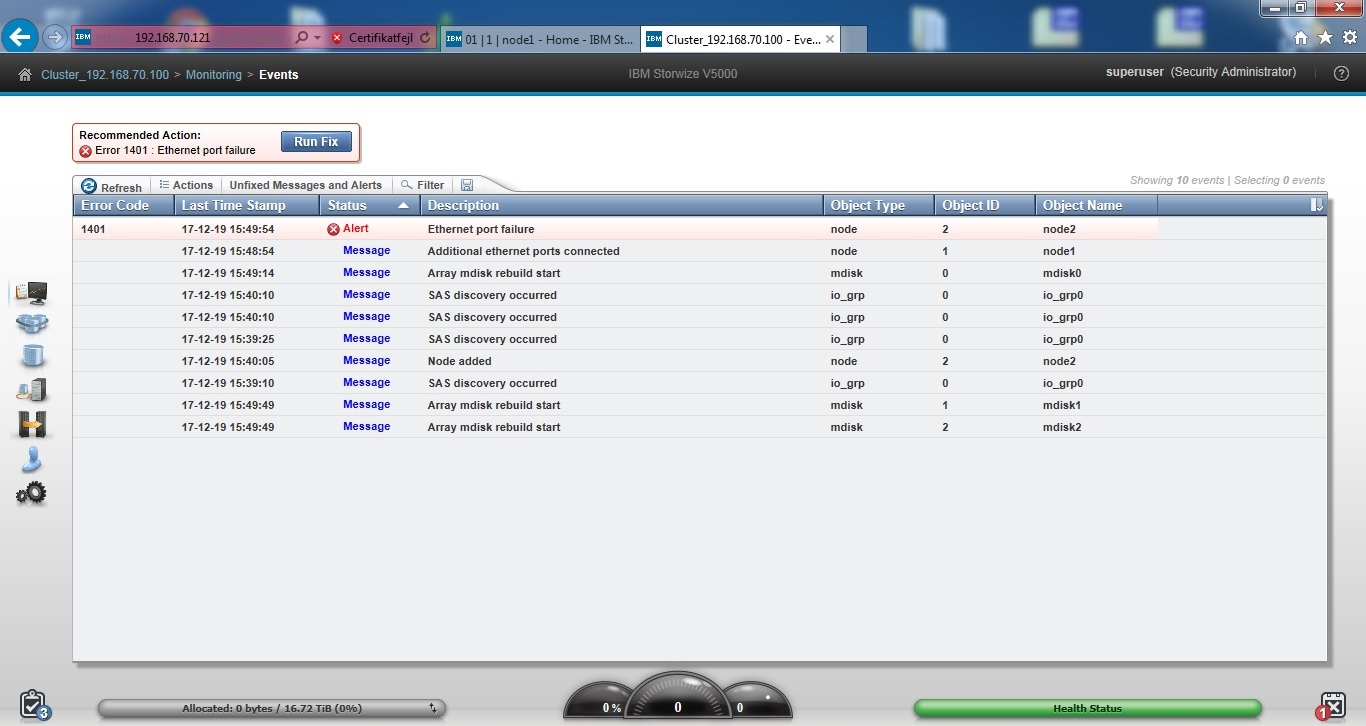
Til sidst kigger vi lige i loggen, mens systemet initialiserer diskene. Den eneste fejl, der fremkommer, er, at der ikke er noget Ethernet kabel i controller 2, så alt ser fint ud. Vi lader systemet køre natten over så initialiseringen kan blive færdig.

Som det sidste skal vi have slettet de diske, der sad i systemet. Alle diskene er flyttet til en expansion skuffe, da Certus ikke kan lave ændringer i controlleren for at kunne slette diskene, vil vi sætte en ”dum” skuffe til en server, der kører Certus.

Serveren, vi primært bruger til at slette diske med, er en HP DL385 G7 med en SAS expander i toppen, så der er understøttelse for 24 interne diske igennem den onboard controller. Under expander kortet sidder et HBA kort, mere specifikt et SC08e SAS HBA fra LSI, men egentlig er Certus ret ligeglad, så længe det er et HBA kort og ikke en controller, vi bruger. HBA kortet bruger kabler kaldet SFF-8088, men SAS porten i expander skuffen er et SFF-8644. Disse to typer kabler har dog samme SAS forbindelse, hvorfor man kan få kabler der har SFF-8088 i den ene ende, og SFF-8644 i den anden. Vi bruger kun det ene I/O modul i expansion skuffen, da Certus ellers vil se hver disk to gange.
Vi sletter diskene med British HMG Baseline algoritmen. Certus understøtter mange forskellige algoritmer, men denne er den hurtigste, der overskriver diskene en enkelt gang og verificerer efterfølgende. Vores erfaring fortæller os, at dette er nok til at ødelægge alt data på diskene. Vi kan dog overskrive mere end en gang, hvis en kunde skulle ønske dette.
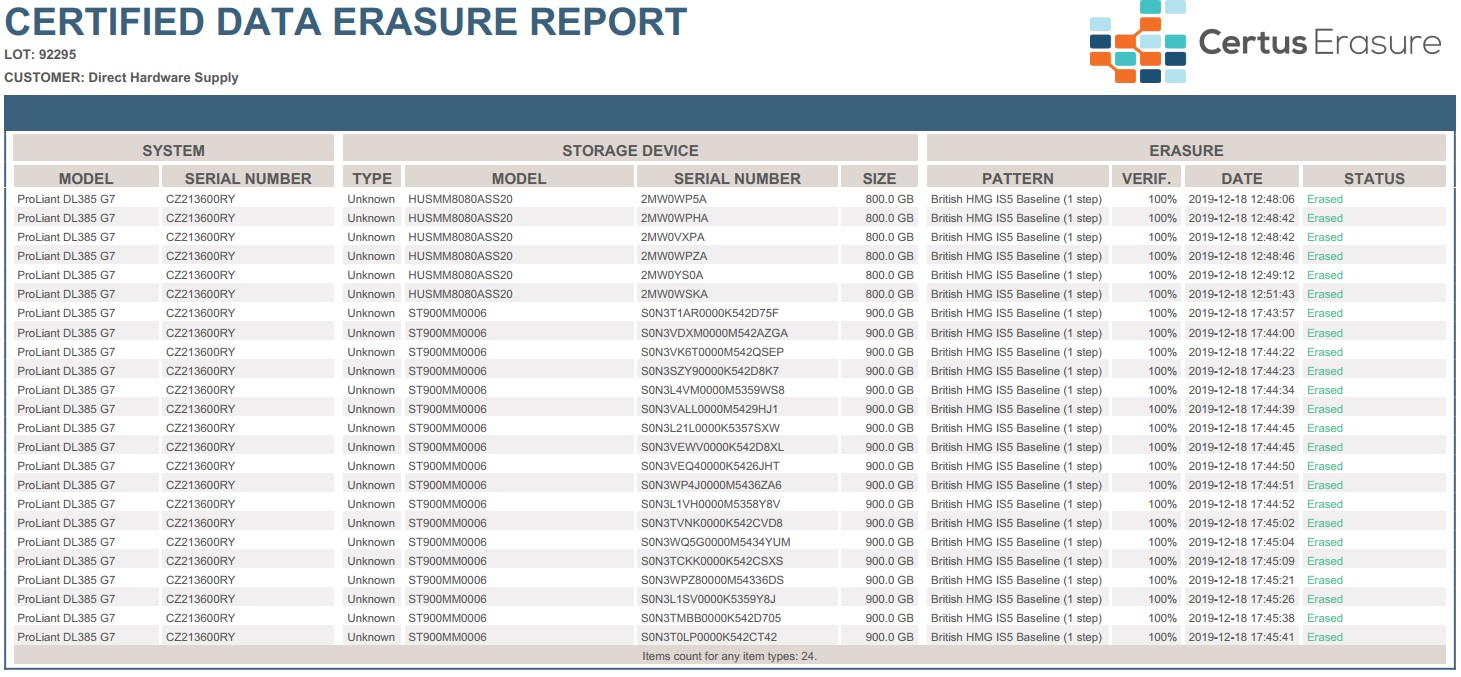
Efter Certus er færdig med at slette diskene, får vi en rapport over, hvordan det er gået. Alle diske er slettet succesfuldt, hvilket også betyder, at diskene har et godt helbred.
CVR NUMMER
32783643
ADRESSE
brugt-it
Jellingvej 26
9230 Svenstrup J